课后练习
编程题
IPC 管道、共享内存、信号量、消息队列例程
-
- 分别编写基于 UNIX System V IPC 的管道、共享内存、信号量和消息队列的 Linux 应用程序,实现进程间的数据交换。
// 管道
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void) {
int pipefd[2];
// pipe syscall creates a pipe with two ends
// pipefd[0] is the read end
// pipefd[1] is the write end
// ref: https://man7.org/linux/man-pages/man2/pipe.2.html
if (pipe(pipefd) == -1) {
perror("failed to create pipe");
exit(EXIT_FAILURE);
}
int pid = fork();
if (pid == -1) {
perror("failed to fork");
exit(EXIT_FAILURE);
}
if (pid == 0) {
// child process reads from the pipe
close(pipefd[1]); // close the write end
// read a byte at a time
char buf;
while (read(pipefd[0], &buf, 1) > 0) {
printf("%s", &buf);
}
close(pipefd[0]); // close the read end
} else {
// parent process writes to the pipe
close(pipefd[0]); // close the read end
// parent writes
char* msg = "hello from pipe\n";
write(pipefd[1], msg, strlen(msg)); // omitting error handling
close(pipefd[1]); // close the write end
}
return EXIT_SUCCESS;
}// 与上面C的管道程序功能相同
#![allow(unused_imports)]
extern crate libc;
use std::ffi::CString;
use std::os::raw::c_char;
use std::os::unix::io::RawFd;
use std::io::Write;
fn main() {
let mut pipefd: [RawFd; 2] = [0, 0];
unsafe {
// 创建管道
if libc::pipe(pipefd.as_mut_ptr()) == -1 {
perror("failed to create pipe");
std::process::exit(libc::EXIT_FAILURE);
}
let pid = libc::fork();
if pid == -1 {
perror("failed to fork");
std::process::exit(libc::EXIT_FAILURE);
}
if pid == 0 {
// 子进程读取管道
libc::close(pipefd[1]); // 关闭写端
let mut buf: [u8; 1] = [0];
loop {
let n = libc::read(pipefd[0], buf.as_mut_ptr() as *mut libc::c_void, 1);
if n > 0 {
print!("{}", buf[0] as char as char);
} else if n == 0 {
break;
} else {
perror("read error");
std::process::exit(libc::EXIT_FAILURE);
}
}
libc::close(pipefd[0]); // 关闭读端
} else {
// 父进程写入管道
libc::close(pipefd[0]); // 关闭读端
let msg = "hello from pipe\n";
let c_msg = CString::new(msg).expect("CString conversion failed");
let msg_ptr = c_msg.as_ptr();
libc::write(pipefd[1], msg_ptr as *const libc::c_void, msg.len() as usize);
libc::close(pipefd[1]); // 关闭写端
}
}
}
fn perror(msg: &str) {
unsafe {
let c_msg = CString::new(msg).expect("CString conversion failed");
libc::perror(c_msg.as_ptr());
}
}
// 共享内存
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/shm.h>
int main(void) {
// create a new anonymous shared memory segment of page size, with a permission of 0600
// ref: https://man7.org/linux/man-pages/man2/shmget.2.html
int shmid = shmget(IPC_PRIVATE, sysconf(_SC_PAGESIZE), IPC_CREAT | 0600);
if (shmid == -1) {
perror("failed to create shared memory");
exit(EXIT_FAILURE);
}
int pid = fork();
if (pid == -1) {
perror("failed to fork");
exit(EXIT_FAILURE);
}
if (pid == 0) {
// attach the shared memory into child process's address space
char* shm = shmat(shmid, NULL, 0);
while (!shm[0]) {
// wait until the parent signals that the data is ready
// WARNING: this is not the correct way to synchronize processes
// on SMP systems due to memory orders, but this implementation
// is chosen here specifically for ease of understanding
}
printf("%s", shm + 1);
} else {
// attach the shared memory into parent process's address space
char* shm = shmat(shmid, NULL, 0);
// copy message into shared memory
strcpy(shm + 1, "hello from shared memory\n");
// signal that the data is ready
shm[0] = 1;
}
return EXIT_SUCCESS;
}// semaphore
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/sem.h>
int main(void) {
// create a new anonymous semaphore set, with permission 0600
// ref: https://man7.org/linux/man-pages/man2/semget.2.html
int semid = semget(IPC_PRIVATE, 1, IPC_CREAT | 0600);
if (semid == -1) {
perror("failed to create semaphore");
exit(EXIT_FAILURE);
}
struct sembuf sops[1];
sops[0].sem_num = 0; // operate on semaphore 0
sops[0].sem_op = 1; // increase the semaphore's value by 1
sops[0].sem_flg = 0;
if (semop(semid, sops, 1) == -1) {
perror("failed to increase semaphore");
exit(EXIT_FAILURE);
}
int pid = fork();
if (pid == -1) {
perror("failed to fork");
exit(EXIT_FAILURE);
}
if (pid == 0) {
printf("hello from child, waiting for parent to release semaphore\n");
struct sembuf sops[1];
sops[0].sem_num = 0; // operate on semaphore 0
sops[0].sem_op = 0; // wait for the semaphore to become 0
sops[0].sem_flg = 0;
if (semop(semid, sops, 1) == -1) {
perror("failed to wait on semaphore");
exit(EXIT_FAILURE);
}
printf("hello from semaphore\n");
} else {
printf("hello from parent, waiting three seconds before release semaphore\n");
// sleep for three second
sleep(3);
struct sembuf sops[1];
sops[0].sem_num = 0; // operate on semaphore 0
sops[0].sem_op = -1; // decrease the semaphore's value by 1
sops[0].sem_flg = 0;
if (semop(semid, sops, 1) == -1) {
perror("failed to decrease semaphore");
exit(EXIT_FAILURE);
}
}
return EXIT_SUCCESS;
}// message queue
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/msg.h>
struct msgbuf {
long mtype;
char mtext[1];
};
int main(void) {
// create a new anonymous message queue, with a permission of 0600
// ref: https://man7.org/linux/man-pages/man2/msgget.2.html
int msgid = msgget(IPC_PRIVATE, IPC_CREAT | 0600);
if (msgid == -1) {
perror("failed to create message queue");
exit(EXIT_FAILURE);
}
int pid = fork();
if (pid == -1) {
perror("failed to fork");
exit(EXIT_FAILURE);
}
if (pid == 0) {
// child process receives message
struct msgbuf buf;
while (msgrcv(msgid, &buf, sizeof(buf.mtext), 1, 0) != -1) {
printf("%c", buf.mtext[0]);
}
} else {
// parent process sends message
char* msg = "hello from message queue\n";
struct msgbuf buf;
buf.mtype = 1;
for (int i = 0; i < strlen(msg); i ++) {
buf.mtext[0] = msg[i];
msgsnd(msgid, &buf, sizeof(buf.mtext), 0);
}
struct msqid_ds info;
while (msgctl(msgid, IPC_STAT, &info), info.msg_qnum > 0) {
// wait for the message queue to be fully consumed
}
// close message queue
msgctl(msgid, IPC_RMID, NULL);
}
return EXIT_SUCCESS;
}- ** 分别编写基于 UNIX 的 signal 机制的 Linux 应用程序,实现进程间异步通知。
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
static void sighandler(int sig) {
printf("received signal %d, exiting\n", sig);
exit(EXIT_SUCCESS);
}
int main(void) {
struct sigaction sa;
sa.sa_handler = sighandler;
sa.sa_flags = 0;
sigemptyset(&sa.sa_mask);
// register function sighandler as signal handler for SIGUSR1
if (sigaction(SIGUSR1, &sa, NULL) != 0) {
perror("failed to register signal handler");
exit(EXIT_FAILURE);
}
int pid = fork();
if (pid == -1) {
perror("failed to fork");
exit(EXIT_FAILURE);
}
if (pid == 0) {
while (1) {
// loop and wait for signal
}
} else {
// send SIGUSR1 to child process
kill(pid, SIGUSR1);
}
return EXIT_SUCCESS;
}-
** 参考 rCore Tutorial 中的 shell 应用程序,在 Linux 环境下,编写一个简单的 shell 应用程序,通过管道相关的系统调用,能够支持管道功能。
-
** 扩展内核,实现共享内存机制。
-
*** 扩展内核,实现 signal 机制。
问答题
直接通信和间接通信的本质区别
-
- 直接通信和间接通信的本质区别是什么?分别举一个例子。
本质区别是消息是否经过内核,如共享内存就是直接通信,消息队列则是间接通信。
signal 机制的内核实现思路
- ** 试说明基于 UNIX 的 signal 机制,如果在本章内核中实现,请描述其大致设计思路和运行过程。
- 首先需要添加两个 syscall,其一是注册 signal handler,其二是发送 signal。
- 其次是添加对应的内核数据结构,对于每个进程需要维护两个表,其一是 signal 到 handler 地址的对应,其二是尚未处理的 signal。
- 当进程注册 signal handler 时,将所注册的处理函数的地址填入表一。
- 当进程发送 signal 时,找到目标进程,将 signal 写入表二的队列之中。
- 随后修改从内核态返回用户态的入口点的代码,检查是否有待处理的 signal。若有,检查是否有对应的 signal handler 并跳转到该地址,如无则执行默认操作,如杀死进程。需要注意的是,此时需要记住原本的跳转地址,当进程从 signal handler 返回时将其还原。
普通管道和匿名管道的异同
- ** 比较在 Linux 中的无名管道(普通管道)与有名管道(named pipe, FIFO 是根据行为的名称)的异同。
- 同:两者都是进程间信息单向传递的通路,可以在进程之间传递一个字节流。
- 异:
- 普通管道不存在文件系统上对应的文件,而是仅由读写两端两个 fd 表示,
- 而 FIFO 则是由文件系统上的一个特殊文件表示,进程打开该文件后获得对应的 fd。这样,即使与 FIFO 的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过 FIFO 相互通信,因此,通过 FIFO 不相关的进程也能交换数据。
- FIFO 在文件系统中作为一个特殊的文件而存在,但 FIFO 中的内容却存放在内存中。
- 当使用 FIFO 的进程退出后,FIFO 文件将继续保存在文件系统中以便以后使用。
// 创建一个管道
int mkfifo(const char *pathname, mode_t mode);
// 打开一个管道
int open(const char *pathname, int flags);
打开 FIFO 文件和普通文件的区别有2点:
第一个是不能以O_RDWR模式打开FIFO文件进行读写操作。这样做的行为是未定义的。
因为我们通常使用FIFO只是为了单向传递数据,所以没有必要使用这个模式。
如果确实需要在程序之间双向传递数据,最好使用一对FIFO或管道,一个方向使用一个。或者采用先关闭在重新打开FIFO的方法来明确改变数据流的方向。
第二是对标志位的O_NONBLOCK选项的用法。
使用这个选项不仅改变open调用的处理方式,还会改变对这次open调用返回的文件描述符进行的读写请求的处理方式。
O_RDONLY、O_WRONLY和O_NONBLOCK标志共有四种合法的组合方式:
- flags=O_RDONLY:open将会调用阻塞,除非有另外一个进程以写的方式打开同一个FIFO,否则一直等待。
- flags=O_WRONLY:open将会调用阻塞,除非有另外一个进程以读的方式打开同一个FIFO,否则一直等待。
- flags=O_RDONLY|O_NONBLOCK:如果此时没有其他进程以写的方式打开FIFO,此时open也会成功返回,此时FIFO被读打开,而不会返回错误。
- flags=O_WRONLY|O_NONBLOCK:立即返回,如果此时没有其他进程以读的方式打开,open会失败打开,此时FIFO没有被打开,返回-1。
open函数调用中的参数标志O_NONBLOCK会影响FIFO的读写操作。
规则如下:
- 对一个空的阻塞的FIFO的read调用将等待,直到有数据可以读的时候才继续执行/
- 对一个空的非阻塞的FIFO的read调用立即返回0字节。
- 对一个完全阻塞的FIFO的write调用将等待,直到数据可以被写入时才开始执行。
- 系统规定:如果写入的数据长度小于等于PIPE_BUF字节,那么或者写入全部字节,要么一个字节都不写入。
注意这个限制的作用:
当只使用一个FIF并允许多个不同的程序向一个FIFO读进程发送请求的时候,为了保证来自不同程序的数据块 不相互交错,即每个操作都原子化,这个限制就很重要了。如果能够包子所有的写请求是发往一个阻塞的FIFO的,并且每个写请求的数据长父小于等于PIPE_BUF字节,系统就可以确保数据绝不会交错在一起。通常将每次通过FIFO传递的数据长度限制为PIPE_BUF是一个好办法。
- 在非阻塞的write调用情况下,如果FIFO 不能接收所有写入的数据,将按照下面的规则进行:
- 请求写入的数据的长度小于PIPE_BUF字节,调用失败,数据不能被写入。
- 请求写入的数据的长度大于PIPE_BUF字节,将写入部分数据,返回实际写入的字节数,返回值也可能是0。
其中。PIPE_BUF是FIFO的长度,它在头文件limits.h中被定义。在linux或其他类UNIX系统中,它的值通常是4096字节。
// write.c
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define FIFO_NAME "/tmp/myfifo"
int main(){
if(access(FIFO_NAME,F_OK) != 0){//如果文件存在
int err = mkfifo(FIFO_NAME,0777);
if(err != 0){
perror("Create fifo failed");
return -1;
}
}
printf("create fifo succeed!\n");
int fifo_fd = open(FIFO_NAME,O_WRONLY);
printf("open fifo succeed!\n");
if(fifo_fd < 0){
printf("open fifo failed!\n");
return -1;
}
int i = 1;
for(;i < 100; i++){
if(write(fifo_fd,&i,sizeof(int)) != -1)
sleep(1);
else
perror("Write failed");
}
printf("write succeed: %d\n",i);
close(fifo_fd);
return 0;
}// read.c
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#define FIFO_NAME "/tmp/myfifo"
int main(){
int fifo_fd = open(FIFO_NAME,O_RDONLY | O_NONBLOCK );
if(fifo_fd < 0){
printf("open fifo failed!\n");
return -1;
}
int i;
sleep(5);
while(1){
int size = read(fifo_fd,&i,sizeof(int));
if(size > 0)
printf("读到:%d\n",i);
}
close(fifo_fd);
return 0;
}匿名管道的特点和适用场景
- ** 请描述 Linux 中的无名管道机制的特征和适用场景。
无名管道用于创建在进程间传递的一个字节流,适合用于流式传递大量数据,但是进程需要自己处理消息间的分割。
$ ps auxf | grep mysql
上面命令行里的 | 竖线就是一个 匿名管道 anonymous pipe,它的功能是将前一个命令(ps auxf)的输出,作为后一个命令(grep mysql)的输入,从这功能描述,可以看出 管道传输数据是单向的 ,如果想相互通信,我们需要创建两个管道才行。
同时,上面这种管道是没有名字,所以 | 表示的管道称为 匿名管道 ,用完了就销毁。
消息队列的特征与适用场景
- ** 请描述 Linux 中的消息队列机制的特征和适用场景。
消息队列用于在进程之间发送一个由 type 和 data 两部分组成的短消息,接收消息的进程可以通过 type 过滤自己感兴趣的消息,适用于大量进程之间传递短小而多种类的消息。
管道的通信方式是效率低的,因此管道不适合进程间频繁地交换数据。
对于这个问题,消息队列的通信模式就可以解决。比如,A 进程要给 B 进程发送消息,A 进程把数据放在对应的消息队列后就可以正常返回了,B 进程需要的时候再去读取数据就可以了。同理,B 进程要给 A 进程发送消息也是如此。
再者,消息队列是保存在内核中的消息链表,在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型,所以每个消息体都是固定大小的存储块,不像管道是无格式的字节流数据。如果进程从消息队列中读取了消息体,内核就会把这个消息体删除。
消息队列生命周期随内核,如果没有释放消息队列或者没有关闭操作系统,消息队列会一直存在,而前面提到的匿名管道的生命周期,是随进程的创建而建立,随进程的结束而销毁。
消息这种模型,两个进程之间的通信就像平时发邮件一样,你来一封,我回一封,可以频繁沟通了。 但邮件的通信方式存在不足的地方有两点,一是通信不及时,二是附件也有大小限制,这同样也是消息队列通信不足的点。
消息队列不适合比较大数据的传输,因为在内核中每个消息体都有一个最大长度的限制,同时所有队列所包含的全部消息体的总长度也是有上限。在 Linux 内核中,会有两个宏定义 MSGMAX 和 MSGMNB,它们以字节为单位,分别定义了一条消息的最大长度和一个队列的最大长度。
消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销,因为进程写入数据到内核中的消息队列时,会发生从用户态拷贝数据到内核态的过程,同理另一进程读取内核中的消息数据时,会发生从内核态拷贝数据到用户态的过程。
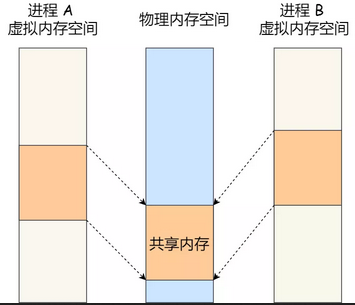
共享内存机制的特征和适用场景
- ** 请描述 Linux 中的共享内存机制的特征和适用场景。
共享内存用于创建一个多个进程可以同时访问的内存区域,故而消息的传递无需经过内核的处理,适用在需要较高性能的场景,但是进程之间需要额外的同步机制处理读写的顺序与时机。
消息队列的读取和写入的过程,都会有发生用户态与内核态之间的消息拷贝过程。那共享内存的方式,就很好的解决了这一问题。
现代操作系统,对于内存管理,采用的是虚拟内存技术,也就是每个进程都有自己独立的虚拟内存空间,不同进程的虚拟内存映射到不同的物理内存中。所以,即使进程 A 和 进程 B 的虚拟地址是一样的,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去,大大提高了进程间通信的速度。
Bash 中 Ctrl+C 产生的信号和处理流程
- ** 请描述 Linux 的 bash shell 中执行与一个程序时,用户敲击 Ctrl+C 后,会产生什么信号(signal),导致什么情况出现。
会产生SIGINT,如果该程序没有捕获该信号,它将会被杀死,若捕获了,通常会在处理完或是取消当前正在进行的操作后主动退出。
Bash 中 Ctrl+Z 产生的信号和处理流程
- ** 请描述 Linux 的 bash shell 中执行与一个程序时,用户敲击 Ctrl+Zombie 后,会产生什么信号(signal),导致什么情况出现。
会产生 SIGTSTP,该进程将会暂停运行(挂起),将控制权重新转回 shell。
- ** 请描述 Linux 的 bash shell 中执行 kill -9 2022 这个命令的含义是什么?导致什么情况出现。
向pid为2022的进程发送SIGKILL,该信号无法被捕获,该进程将会被强制杀死。
- ** 请指出一种跨计算机的主机间的进程间通信机制。
gRPC、TCP 协议
实验练习
实验练习包括实践作业和问答作业两部分。
本次难度也就和 lab3 一样吧
编程作业
进程通信:邮箱
这一章我们实现了基于 pipe 的进程间通信,但是看测例就知道了,管道不太自由,我们来实现一套乍一看更靠谱的通信 syscall 吧!本节要求实现邮箱机制,以及对应的 syscall。
- 邮箱说明:每个进程拥有唯一一个邮箱,基于 “数据报” 收发字节信息,利用环形 buffer 存储,读写顺序为 FIFO,不记录来源进程。每次读写单位必须为一个报文,如果用于接收的缓冲区长度不够,舍弃超出的部分(截断报文)。为了简单,邮箱中最多拥有 16 条报文,每条报文最大长度 256 字节。当邮箱满时,发送邮件(也就是写邮箱)会失败。不考虑读写邮箱的权限,也就是所有进程都能够随意给其他进程的邮箱发报。
mailread:
syscall ID:401
Rust 接口:
fn mailread(buf: *mut u8, len: usize)功能:读取一个报文,如果成功返回报文长度.
参数:
buf: 缓冲区头。
len:缓冲区长度。
说明:
len > 256 按 256 处理,len < 队首报文长度且不为 0,则截断报文。
len = 0,则不进行读取,如果没有报文读取,返回 - 1,否则返回 0,这是用来测试是否有报文可读。
可能的错误:
邮箱空。
buf 无效。
mailwrite:
syscall ID:402
Rust 接口:
fn mailwrite(pid: usize, buf: *mut u8, len: usize)功能:向对应进程邮箱插入一条报文.
参数:
pid: 目标进程 id。
buf: 缓冲区头。
len:缓冲区长度。
说明:
len > 256 按 256 处理,
len = 0,则不进行写入,如果邮箱满,返回 - 1,否则返回 0,这是用来测试是否可以发报。
可以向自己的邮箱写入报文。
可能的错误:
邮箱满。
buf 无效。
实验要求
-
实现分支:ch6-lab
-
实验目录要求不变
-
通过所有测例
在 os 目录下
make run TEST=1加载所有测例,test_usertest打包了所有你需要通过的测例,你也可以通过修改这个文件调整本地测试的内容。你的内核必须前向兼容,能通过前一章的所有测例。
challenge: 支持多核。
问答作业
-
举出使用 pipe 的一个实际应用的例子。
-
共享内存的测例中有如下片段 (伪代码):
int main()
{
uint64 *A = (void *)0x10000000;
uint64 *B = (void *)(0x10000000 + 0x1000);
uint64 len = 0x1000;
make_shmem(A, B, len); // 将 [A, A + len) [B, B + len) 这两段虚存映射到同一段物理内存
*A = 0xabab;
__sync_synchronize(); // 这是什么?
if(*B != 0xabab) {
return ERROR;
}
printf("OK!");
return 0;
}
请查阅相关资料,回答 __sync_synchronize 这行代码的作用,如果去掉它可能会导致什么错误?为什么?
__sync_synchronize() 是一个内置的函数,通常在多线程或多进程编程中用于确保内存访问的顺序性和一致性。在你的代码示例中,它的作用是确保对共享内存中的数据的正确同步,以防止出现竞态条件或乱序执行问题。
在具体解释它的作用之前,让我们先理解一些相关的背景知识:
-
多线程/多进程并发问题: 当多个线程或进程同时访问共享的内存区域时,可能会发生不同步的问题。这些问题包括数据竞争、乱序执行、缓存不一致等,这些都可以导致程序出现不可预测的行为。
-
内存屏障(Memory Barrier): 内存屏障是一种用于确保内存操作顺序的机制。在多核处理器上,不同核之间的缓存可能会导致内存操作看起来是乱序的。内存屏障能够强制确保某些操作的执行顺序,以维护程序的一致性。
__sync_synchronize() 是一种内存屏障,它的作用是:
- 确保在该函数之前的所有内存操作被按顺序执行,且在该函数之后的内存操作不会被提前执行。
- 防止编译器和处理器对代码进行优化,以确保在内存屏障之前和之后的内存访问按照程序员的意图进行排序,而不是被重新排列。
在你的代码示例中,__sync_synchronize() 的作用是确保在将数据写入共享内存 *A = 0xabab; 之后,这个写操作不会被重排序到 if(*B != 0xabab) 的前面。这保证了在检查 *B 的值之前,确实已经将数据 0xabab 写入了共享内存中。这是非常重要的,因为如果没有内存屏障,处理器和编译器可能会重新排列这些操作,导致错误的结果。
综上所述,__sync_synchronize() 在这里的作用是确保内存操作的顺序性,以维护共享内存的一致性,从而避免潜在的并发问题。
实验练习的提交报告要求
-
简单总结本次实验与上个实验相比你增加的东西。(控制在 5 行以内,不要贴代码)
-
完成问答问题
-
(optional) 你对本次实验设计及难度的看法。