1. 设计背景总结
动机
- AI 训练需求:分布式 AI 训练(尤其是大规模 LLM)需要高带宽、低延迟、高可靠的数据中心网络支持,传统 TCP/IP 或专有互联(如 InfiniBand)存在 CPU 开销大、延迟高或灵活性不足的问题。
- Meta 选择 RoCEv2 构建专用后端网络:
- 兼容以太网生态,复用现有数据中心基础设施(如 Clos 拓扑)。
- 支持 RDMA verbs 语义,支持 RDMA 访问降低 CPU 开销,并且无缝衔接训练框架(如 NCCL)。
- 开源标准支持多厂商兼容,降低部署成本。
硬件设施
-
训练节点架构:
- 采用 ZionEX 和 Grand Teton 两种平台(前者是 A100,后者是 H100)
- Grand Teton 平台:8 个 GPU 通过 NVSwitch 全互连,每 GPU 配专用 400G RDMA NIC,对于需求少于 8 个 GPU 的任务则在节点内相互通信,多于 8 个的任务则启用 GPUDirect 技术绕过主机内存瓶颈实现高效的 GPU-to-GPU 通信。
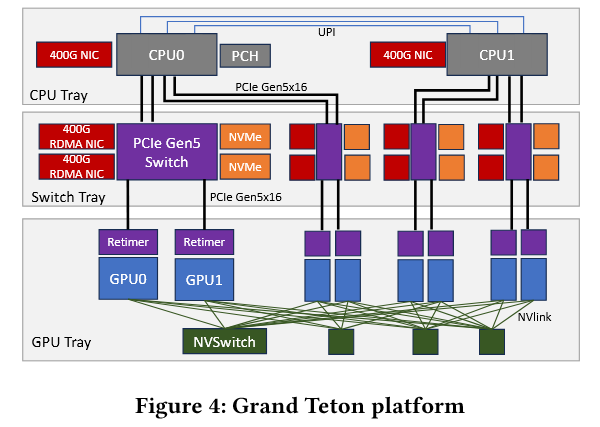
-
网络架构:
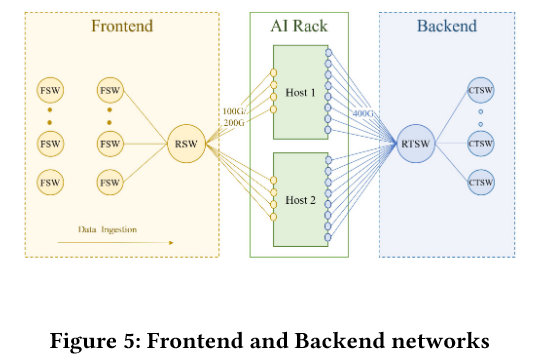
- 前端网络(FE):处理数据输入、日志等非训练流量,基于传统分层架构(RackSWitch、FabricSWitch)。
- 后端网络(BE):专用 RoCEv2 协议(将 RDMA 服务封装在 UDP 包中从而在网络中传输),采用 2-stage Clos 拓扑(称为 AI Zone,利用 RTSW 叶交换机 + CTSW 脊交换机),支持非阻塞通信,支持 DC 级扩展,提供高带宽、低延迟、无丢包的 GPU 间通信。
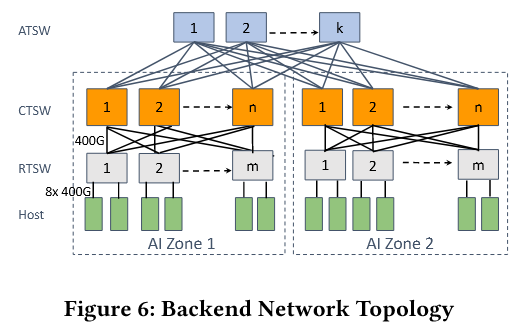
- 扩展性设计(DC-scale 集群):
- LLM 所需的 GPU 规模超出了单个 AI Zone 的能力,为此设计了一个 ATSW 层,用于连接数据中心建筑中的 CTSW,将 RoCE 域扩展到单个 AI 区域之外,通过 ATSW 层连接多 AI Zone,支持数万 GPU 规模。
- 需要注意的是,跨 AI Zone 的连接在设计上是过载的,网络流量通过 ECMP 进行平衡。为了缓解跨 AI Zone 流量的性能瓶颈,Meta 增强了训练作业调度器,在将训练节点分配到不同 AI 区域时寻找“minimum cut”,从而减少跨 AI Zone 的流量,进而缩短集体完成时间。调度器通过学习 GPU 服务器在逻辑拓扑中的位置来推荐排名分配(即拓扑感知任务分配)。
2. 路由设计分析
核心挑战
- 低熵流量:AI 训练流量(如 AllReduce、AlltoAll)的 UDP 五元组重复性高,且流模式通常具有重复性和可预测性,导致 ECMP 哈希冲突,引发链路负载不均。
- 突发性与大象流:集体通信产生瞬时高带宽需求(毫秒级的粒度),易触发 NIC 缓冲区拥塞。
技术设计
-
ECMP and Path Pinning:
- ECMP 问题:默认 ECMP 依赖五元组哈希,但 LLM 训练流量熵低(如 AllReduce 流量模式固定),导致哈希碰撞、链路负载不均(MMR >1.2)。
- 路径固定问题:基于目的“slice”静态路由(slice 指的是 RTSW 下行链路的索引),但针对作业部分分配的机架会导致流量分布不均和上行链路拥塞,故障时 ECMP 重路由加剧冲突。
- 短期解决方案:临时通过 RTSW 上行链路与下行链路的带宽超配(1:2)缓解拥塞,但成本高昂。
-
Enhanced ECMP with QP Scaling:
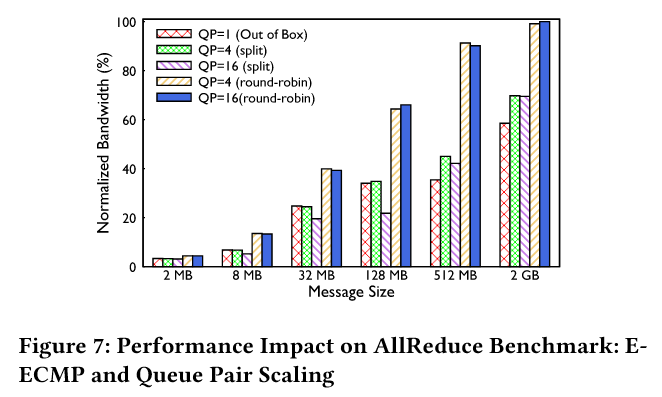
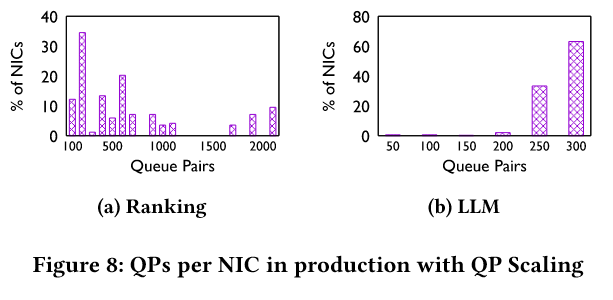
- QP Scaling:通过 NCCL 库将单 NIC-NIC 流拆分为多 Queue Pair(QP)流,增加流数量(QP=16 用于 LLM,QP=4 用于 Ranking),从而增加熵(但调试中发现,并没有期望的那样大幅提高,例如目标 UDP 端口对于不同的 QP 数据包保持相同,但在某些情况下,源 UDP 端口也保持相同)。
- 定制哈希:在交换机 ASIC 中利用 UDF 扩展哈希字段(如 RoCE 包的 QP 号),从而增加熵值、提升 ECMP 效率。
- 效果:AllReduce 性能提升 40%,但由于 QP 资源有限,需根据不同工作负载调整 QP 数量(如 Ranking 用 4 QP,LLM 用 16 QP)
 ,
, 
- 缺陷:虽然通过 QP 放缩改进了 ECMP 性能,但哈希的概率性负载均衡是该路由方案的一个持久缺点。此外,需要根据工作量类型定制 QP 放缩因子和方法,虽然短期可行,但长期操作复杂。
-
Centralized Traffic Engineering:
- 架构:
- 控制平面:
- 收集端到端训练集群的实时拓扑(Open/R 协议)、流量矩阵(通过流量工程将来自流量矩阵收集器服务的 flow matrix 和 来自训练任务调度器的 job placement 进行组合,导出得到流量矩阵,即 CTE 分配的流的字节计数器),CTE 通过 CSPF 算法处理实时拓扑和流量矩阵,周期性地产出最优 flow placement。
- 交换机编程器(Switch Programmer)将 flow placement 翻译为特定设备的数据平面原语,从而强迫执行路由决策。
- 数据平面:CTE 通过 EM(Exact Match)表覆盖 RTSW 上的默认 BGP 路由决策,从而为 RDMA 流量提供主路由,按
<源端口, 目的前缀>精细流管理,实现精确匹配转发。
- 控制平面:
- 优势:在 128 GPU 测试中,AllReduce 和 AlltoAll 性能提升 5-10%,链路利用率更均衡(80% vs. ECMP 的 40-90%)。
- 局限性:软件复杂、容错性差(多链路故障下性能下降),运维复杂度高(需维护动态状态)、不适合超大规模 DCN 部署。
- 架构:
-
Comparing CTE and E-ECMP:
- 生产作业放置的仿真结果表明,在非最优作业调度场景下,每个
<source-destination>pair 使用 QP=4 的 E-ECMP 平均比 roofline 完成时间长 40%。将 QP 扩展增加到 32 可以改善性能:最坏情况从 roofline 的 20%到 52%。然而,大多数作业无法达到 roofline。相比之下,具有实际需求的 CTE 在网络容量充足时可以实现 100%的利用率。然而,当链路可用性因故障而降低到小于1:1的订阅比时,CTE 可能被 E-ECMP 超越。 - 在受控环境中,Meta 观察到使用真实世界的 NCCL 基准测试的 CTE 在 16 条上行链路的设置中比 E-ECMP 实现了更均衡的链路利用率。使用 E-ECMP 时,链路利用率变化较大:40-90%的最大带宽,而 CTE 均匀利用 80%的最大带宽,减少了最坏情况。图 10 显示,在固定大小(128 个训练节点)的情况下,CTE 在 AllReduce 和 AlltoAll 集合操作中比 E-ECMP 高出 5-10%。

- CTE 的操作经验与教训:在基于排名的 AI Zone 中应用 CTE,并将 E-ECMP 作为备用路由方案以处理受故障影响的流量。可以观察到,CTE 在有效负载均衡方面与早期的路径固定路由方案相似,表现良好,如第 6.2 节仿真中所建模并通过基准测试所测量。然而仿真和部署表明,当网络中发生多个链路故障时,CTE 也容易出现性能下降。最初 Meta 在仿真中认为这些情况是罕见的,但在实践中,它们发生的频率比预期的要高。此外,CTE 还增加了软件复杂性和管理开销。虽然在 AI Zone 部署中这是可以管理的,但 Meta 选择不在数据中心规模上使用 CTE,因为随着网络规模的显著增加,这种额外的复杂性/开销会更大,在计算上,处理另一层交换机(ATSWs)和伴随的路径多样性也增加了负载。因此,E-ECMP 为数据中心规模集群提供了更好的操作权衡。因此,CTE 是大多数针对排名工作负载的集群的主要路由方案,而 E-ECMP 是数据中心规模部署的主要路由方案。
- 生产作业放置的仿真结果表明,在非最优作业调度场景下,每个
-
Future Direction: Flowlet Switching):
- 机制:检测流间间隙,利用流量微突发间隔(256-512μs)动态切换路径,基于端口负载选择初始路径,兼顾负载均衡与低乱序。
- 优势:
- 硬件加速(交换机 ASIC 实现),响应时间微秒级。
- 初始路径选择基于负载,减少哈希依赖。动态负载均衡优于 ECMP,接近 CTE 性能(测试中乱序包<1 pkt/s)。
- 挑战:需调优流间隔(256-512μs)以平衡乱序与负载均衡(间隔≈½ RTT)。
3. 路由设计的性能改善分析
Co-tuning Network and Collective(网络与集体库协同调优)
NCCL 默认配置的局限性:NCCL 开发人员的环境与实际生产环境不同,开发人员环境假设为:非常低的 RTT 延迟(<10μs)、自适应路由机制、无 oversubscription 的非阻塞拓扑。这些假设在整个体系结构中导致了次优选择——包括发布较小消息时的两阶段复制;依赖于关键路径中控制消息的接收方驱动架构;以及有限的逻辑拓扑选择(这些选择会在大型组,例如,AllGather 的环形拓扑中累积延迟)。
具体问题的调优策略:
-
Higher unloaded RTT:生产环境中由于CTSW交换机使用虚拟输出队列(VOQ)架构,因此需要从出口队列到入口队列交换信用(credit)信息,因此产生较高的无负载 RTT(22μs)。
- 调优策略:1)高延迟要求增大通道缓冲区和发布到网络的消息的大小,确保网络上有更多的未完成数据,使其刚好足够以实现最佳性能。发布较大的消息有助于减少CTS和完成消息的数量。2)针对 CTSW latency 优化,VOQ 架构的 CTSW 从出口端口到入口端口使用更积极的信用分配,包括初始分配以及信用增长的曲线——这种调优对于像AllGather和ReduceScatter这样对延迟敏感的集合通信操作在小规模情况下性能提升了高达 15%。
-
Rendezvous message performance impact:接收方驱动的通信架构依赖于集合消息,如清除发送(Clear-to-Send)和确认(ACK),在生产中,拥塞积累会延迟这些消息的返回。
- 调优策略:对NCCL进行工具化,以测量发送方等待此类数据包(CTS/ACK)的平均延迟。通过更改 CTS 消息的 QoS 优先级实现集体库的更改,对于 ACK 数据包,使用 RTSW ASIC 功能修改 DSCP 标记,使其进入不同的优先级。由此,延迟从P90的43μs减少到4μs。
-
Small messages:NCCL通过以下两种策略为小规模集体操作提供最佳性能:1)使用不同的逻辑拓扑来实现相同的集体操作,例如树形与环形;2)使用不同的低延迟或高带宽协议,例如Simple、LL128、LL(低延迟),以处理跨越GPU内存到PCIe / RDMA边界或反方向的内存屏障。每种拓扑或协议可能对小规模或大规模集体操作都是最优的,然而何时使用特定逻辑拓扑或协议的调优是基于假设的低延迟(包括负载和无负载)静态调优模型计算的,这导致了不利的权衡和较差的性能。
- 调优策略:调整调优算法,选择递归逻辑拓扑(树形)或在网络上发布较大消息的拓扑(Rail-based Alltoall),用于减少延迟累积;在比默认NCCL choice 更大的集体规模上,针对不同集体通信类型(如AlltoAll、AllReduce),选择低延迟协议(LL128)或高带宽协议(Rail-based)。
-
Other enhancements:其他改进包括调整NIC PCIe信用和宽松排序;网络拓扑感知的等级分配;以及消除由NIC发送的零字节消息的原因,这些消息不被以太网交换机支持但被InfiniBand支持。
-
改进效果:
- 通过协同调优(如通道数优化、缓冲区大小调整),RoCE 性能提升超过 2 倍(图 15)
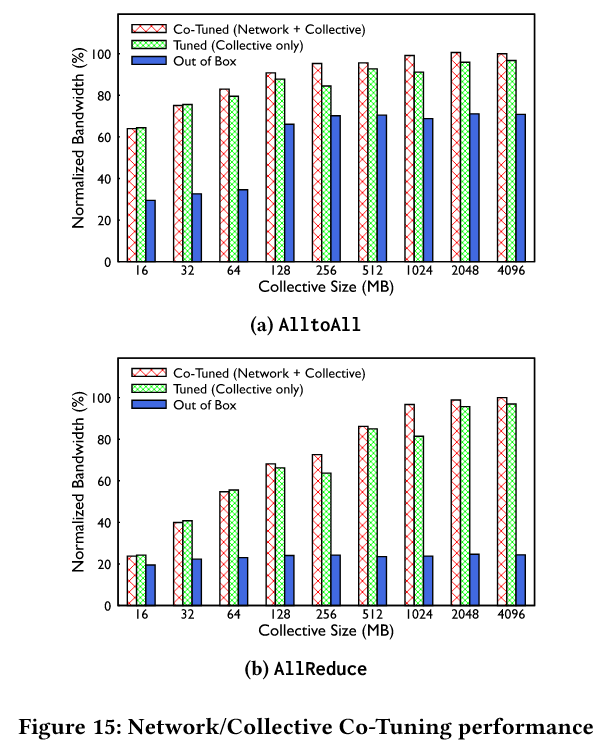
- 特定场景(如 AllReduce)的吞吐量从基线 40%提升至接近理论极限(roofline)。
- 通过协同调优(如通道数优化、缓冲区大小调整),RoCE 性能提升超过 2 倍(图 15)
Impact of Routing and Topology(路由与拓扑的影响)
实验阶段对比(图 16):
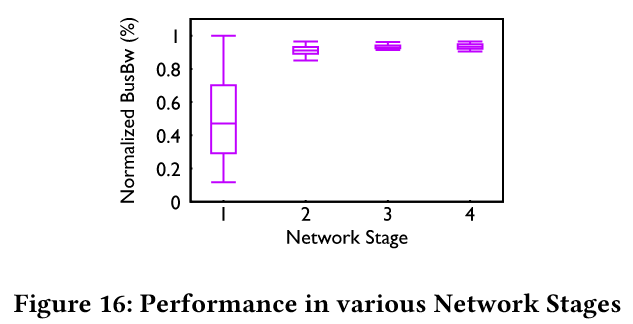
| 阶段 | 配置 | 性能表现 |
|---|---|---|
| Stage 1 | ECMP+静态路由 + 1:1带宽 | 性能低且波动大(哈希碰撞导致链路拥塞),需 1:2 过量订阅临时缓解(stage2) |
| Stage 2 | 1:2带宽超配 | 性能提升,但成本高昂(硬件资源浪费) |
| Stage 3 | CTE 路由 + 1:2带宽 | 性能稳定(MLU 40-90% →80%),接近 Stage 2 且无需超配 |
| Stage 4 | CTE 路由 + 1:1.125 带宽 | 通过跨AI Zone的拓扑感知调度,减少跨区域流量,进一步降低订阅比。带宽利用率优化,支持冗余链路容错 |
-
ECMP → E-ECMP with QP Scaling
- 问题:默认 ECMP 因流量熵低导致哈希碰撞,链路利用率不均(MMR >1.2),AllReduce 性能波动大(图 16 Stage 1)。
- 改进:
- QP Scaling:通过 NCCL 库将单流拆分为多 QP 流(如 LLM 任务 QP=16,Ranking 任务 QP=4),结合交换机 UDF 功能哈希 QP 字段。
- 性能提升:
- 仿真中,E-ECMP + QP Scaling 使 AllReduce 完成时间较基线 ECMP 提升 40%(图 7)。
- 生产环境(Stage 2):通过 RTSW 上行带宽超配(1:2),AllReduce 带宽稳定性提升,但成本高昂(图 16)。
-
E-ECMP → 集中式流量工程(CTE)
- 问题:E-ECMP 在链路故障或非均匀任务分配时性能下降(如多链路故障时仿真性能劣化 20-52%)。
- 改进:
- 动态路径优化:CTE 每 30 秒通过 CSPF 算法动态计算最优路径,结合实时拓扑(Open/R)和流量矩阵;覆盖 BGP 默认路由,支持
<src_port,dst_port>精确匹配转发。
- 动态路径优化:CTE 每 30 秒通过 CSPF 算法动态计算最优路径,结合实时拓扑(Open/R)和流量矩阵;覆盖 BGP 默认路由,支持
- 性能表现:
- 仿真中,CTE 在无故障时实现 100%链路利用率,优于 E-ECMP。
- 生产环境(Stage 3):AllReduce 带宽波动减少(图 16),128 GPU 任务中 CTE 较 E-ECMP 性能提升 5-10%(图 10)。
- 表 3 显示,CTE 下无 PFC 反压(Gather Collective 场景),拥塞被 CTS 缓冲吸收

- 核心结论:CTE 显著提升负载均衡精度,但软件复杂且容错性差(多链路故障时性能劣化),仅适合中小规模集群。
-
CTE → Flowlet Switching(未来方向)
- 问题:CTE 在 DC 级部署中复杂度高,Flowlet 尝试结合动态性与低开销。
- 改进:
- 动态路径切换:基于流量间隔(256-512μs)和端口负载进行动态重分配路径,硬件辅助实现微秒级流切换。
- 性能表现:
- Alltoall 集体通信测试中,512μs 流间隔下乱序包率<1 pkt/s(图 11),性能接近 CTE 且无需 QP Scaling 调优(所以多故障场景下稳定性更强)
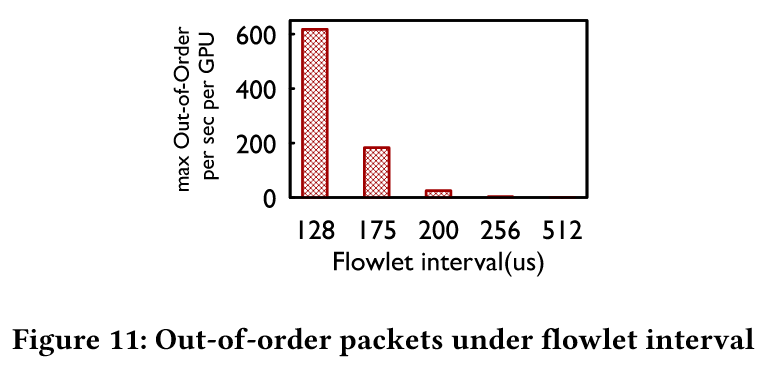
- 初始路径选择基于实时负载(非哈希),减少碰撞概率,AlltoAll 性能提升显著(实验未展示具体数值)。
- Alltoall 集体通信测试中,512μs 流间隔下乱序包率<1 pkt/s(图 11),性能接近 CTE 且无需 QP Scaling 调优(所以多故障场景下稳定性更强)
- 核心结论:Flowlet 在负载均衡和复杂度间取得平衡,硬件支持使其更适合超大规模 DC 部署,但需验证生产稳定性。
| 方案 | 负载均衡 | 运维复杂度 | 故障容忍 | 适用场景 | 性能提升 |
|---|---|---|---|---|---|
| ECMP | 差(MMR>1.2) | 低 | 低 | 小规模、高熵流量 | baseline |
| E-ECMP+QP Scaling | 中等(依赖 QP 配置) | 中等(需硬件超配,QP 资源有限) | 中等 | 中等规模、分层集体通信 | AllReduce 提升 40%(stage2) |
| CTE | 优(80%均衡) | 高 | 弱(多故障) | 中小集群、负载需求精确 | AlltoAll 提升 5- 10% |
| Flowlet Switching | 优(动态适配) | 低(硬件实现) | 强 | 超大规模、动态流量 | 吞吐量接近理论峰值,乱序包<1 pkt/s,硬件低开销 |
Observability Tools(观测工具)
- Job-facing Network Errors:RDMA对网络问题非常敏感,会影响GPU训练效率。为了快速检查训练工作流背后的RDMA网络状况,Meta 构建了遥测系统,自动收集跨网络交换机、NIC、PCIe交换机和GPU的RDMA硬件计数器:
- Out-of-Sequence(乱序包计数器):检测到未上报的交换机丢包事件,帮助定位硬件故障(如 NIC 缺陷)。
- Link Flap Counters(链路抖动计数器):指示 NIC 报告的硬件和软件抖动。
- Local Ack Timeouts(本地确认超时计数器):发送端 QP 的 ACK 计时器超时次数。
- Operator-facing Network Errors:除了监控和检测异常,还要自动执行缓解措施:
- RoCET:总结上述计数器的信息,在用户作业失败时向其直接反馈网络错误(如丢包、延迟),表示网络中一些组件出现故障。
- PFC Watchdog:在 RTSW 和 CTSW 设备上启用,捕获超过 200ms 的 PFC 暂停事件,因为这可能是由于死锁或持续发送 PFC 帧的故障网卡引起的。
- Buffer thresholds and Congestion Drops:在RTSW设备上监控缓冲区利用率,如果缓冲区利用率超过80%,则会触发警报,这表明存在持续拥塞或软件缺陷。同时还监控因拥塞导致的丢包,由于使用的是无损网络,这些丢包情况较为罕见,通常是由于配置错误引起的。
- Reachability:定期通过向各个节点发送ping来检查集群的健康状况和连接性,以检测网络中的存活状态或异常丢包和延迟。
Troubleshooting Examples(故障排查案例)
- 案例 1:性能基线异常
- 问题:CTSW 固件升级导致端口间延迟增加,AllReduce 性能下降。
- 原因与解决:固件内部调度策略变更,增加端到端延迟。通过回滚固件版本,建立加载/空载延迟基线监控,推动厂商修复包调度算法。
- 启示:需持续监控网络延迟(负载与空闲状态),建立性能基线。
- 案例 2:动态流量引发的丢包
- 问题:H100 GPU 高 I/O 需求+固件升级+突发流量导致 CTS 缓冲溢出丢包。
- 原因与解决:H100 GPU高带宽需求 + 突发流量 + 固件缺陷。修复缓冲配置和管理策略,引入合成流量测试验证稳定性,增强变更验证流程。
- 启示:实验性训练任务的动态性需更灵活的监控和自动化修复机制。
4. 优化空间与潜在方向
现有不足
- CTE 的运维开销:动态状态维护复杂,跨 Zone 扩展性差。
- 流切换的硬件依赖:需交换机 ASIC 支持,流间隔调优需更多场景验证。
- 拥塞控制协同:当前依赖接收端驱动(NCCL CTS 机制),与路由层联动不足。
优化方向
-
混合路由策略:
- CTE+Flowlet:CTE 处理静态大流,Flowlet 动态调整小流,降低状态维护压力。
- AI 任务感知路由:结合调度器分配的拓扑信息,预分配路径(如 AlltoAll 的全网状流量优先跨叶脊均衡)。
-
智能预测与动态调优:
- 机器学习预测流量模式:基于历史任务特征(如集体类型、消息大小)预配置 QP Scaling 与哈希策略。
- 在线流调度:利用可编程交换机(如 P4)实时检测大象流并重路由。
-
硬件加速与协议优化:
- RoCEv3 扩展:增加流量类型字段(如集体 ID),支持交换机按任务类型定制哈希。
- 拥塞控制与路由联合优化:通过 DCQCN 标记结合路径权重,动态规避拥塞链路。
-
动态参数调优:
- Flowlet 间隔自适应:根据实时 RTT 与流量模式动态调整间隔,平衡乱序包与负载均衡粒度。
- QP 资源分配:结合负载预测(如 Chakra 追踪作业特征),动态分配 QP 数量。
-
智能路由算法:
- 机器学习辅助:利用流量矩阵历史数据训练模型,预测拥塞热点并优化路径分配。
- 混合策略:CTE 用于关键流量(如 AlltoAll),Flowlet 处理常规流量,分层管理。
-
硬件增强:
- 深度缓冲优化:在 CTSW 中设计差异化缓冲策略,优先吸收突发流量(如 AlltoAll 微突发)。
- 无损传输改进:结合 HPCC(高精度拥塞控制)与 RoCE,减少 PFC 依赖。
-
跨层协同:
- NCCL 与网络联动:将网络状态(如拥塞信号)反馈至 NCCL,动态调整集合算法(如 Ring/Tree 切换)。
- 拓扑感知调度:在作业调度器中集成网络拓扑信息,避免热点链路分配。
-
自动化调优:开发工具自动根据网络状态(如 RTT、拥塞信号)动态调整 NCCL 参数(通道数、缓冲区)。
-
Flowlet 的规模化验证:需在生产环境中测试 Flowlet 的乱序包率和故障恢复能力,明确其 DC 级适用性。
-
跨层协同设计:将网络拓扑信息集成至作业调度器(如 Chakra),避免热点链路分配,减少哈希碰撞。
-
硬件标准化:推动交换机厂商支持 Flowlet、UDF 哈希等特性,降低定制化依赖。